Ubuntu20.04にchia GUIをインストールする
はじめに
とりあえずprotable plotが実装されるまで暇なので、plotファイルを作成していたPCからWindows10を消してUbuntuで環境構築をすることが目標です。
そんなに難しくなかったので、今回の記事はサクッとしてます。
とりあえずUbuntu20.04のインストール
jp.ubuntu.com
こちらからまずはUbuntu20.04のisoをダウンロードします。最新は一応21.04らしいですが、ちょうど自分のメインPCの中にあったのが20.04のisoファイルだったのでそれをインストールしました。多分20.10でも21.04でもそんなに今回の手順は変わりません。ただ、18.04未満のバージョンだとちょっと変わり、18.04だと追加でpython3.7のインストールが必要になってきます。これに関しては自分の使い慣れている物と手間と相談してください。
一応今回はchiaをGUIで操作したいので、UbuntuもServerではなくGUI付きのバージョンにしてます。
ダウンロードしたらisoファイルをboot出来るようにメディアに焼きます。自分はRufusというソフトをよく使ってます。こいつはRaspberryPiのOSを焼くのにもお世話になってます。
焼いたらインストールです。インストール自体はそんなに難しくないのでスキップ。インストールしたら各々IP固定やsshの設定などしてください。多分今後sshでの操作が便利になっていくと思うので。
chiaのインストール
debファイルもあるらしいのですが、いつもdebファイルはあんまりうまくいかない印象なのでcmdからインストールしていきます。
今回参考にしたサイトはこちら。
github.com
まずはapt-getの更新
sudo apt-get update sudo apt-get upgrade -y
パッケージ内のデータを更新します。インストールしたてなので、中の更新はした方がいいでしょう。
そうしたらgitをインストールします。
sudo apt install git -y
次に、chiaをインストールするディレクトリに移動します。場所は好きなところで。移動したらgitでcloneします。
git clone https://github.com/Chia-Network/chia-blockchain.git -b latest --recurse-submodules
ちょっとだけ時間かかります。cloneしたらディレクトリを移動してインストール用に用意されたshellスクリプトを走らせます。
cd chia-blockchain sh install.sh
インストールのshellスクリプトを走らせれば環境構築や必要なソフトのインストールはやってくれます。このインストールは内容が多いのでgitのcloneより時間はかかります。ただ、待っていれば終わります。
そしたら最後にactivateします。
. ./activate
chia GUIのインストールと起動
ここまででとりあえずchiaのインストールは完了してます。なので、CLIでplotやFarmingを行う場合はこの状態でプロセスを走らせれば動きます。ただ、とりあえず今までWindowsでGUIを使って慣れているのでこちらでもGUIをインストールします。
install.shと同じディレクトリにinstall-gui.shがありますので、それを走らせます。
sh install-gui.sh
こいつもいい感じに時間がかかりました。終わればディレクトリを移動して起動してねって言われます。なのでそのようにやれば起動します。
cd chia-blockchain-gui npm run electronic &
これで今まで見慣れたchiaのクライアントが起動します。ちなみに、末尾に&を付けているのでchiaはバックグラウンドプロセスで走ります。cmdを終了してもタスクとして走ってますので、終了する場合はタスクからkillしてください。
npmってなんのソフトかと思ったら、Node.jsのパッケージを管理してるソフトか。chiaのgithubちょっと興味あってみてみたけど、pythonがメインだけどjsやc++も使って書かれているんだね。
chiaのwallet引き継ぎ
WIndowsと同じwalletを使用するために、Seedを確認して入力します。以前作成したwalletがある場合、左のKeysから目のマークのSee private keyを押します。そうするとPrivate Key,Public Key,Seedが確認できます。今回はこのSeedを使います。24個の英単語のやつですね。
これをUbuntu側から入力します。
入力すると今まで通り使用することができます。
ただ、注意したほうがいい事として、Plotファイルを動かす際に前の機械からFarmingしているという情報を消してください。そうしないと二重マイニングになってしまいます。Plotからディレクトリを消して、HDDを新しい端末に刺し、PlotsのタブからAdd Plot Directoryを選択してplotファイルがある場所を選択します。
この際、新しく刺したhddはどこかのディレクトリにマウントしてください。マウントってなんじゃいって人に説明しますと、Ubuntuで外付けドライブをフォルダとして認識できるようにする際に必要な操作の事です。Windowsだと自動でDドライブとかEドライブとかに設定されるやつです。
出来る人はmountコマンドから、できない人はUbuntuにディスクというソフトが入っているのでそれを使ってGUIからマウントする事が可能です。マウントしたいパーティションを選択して下にある▶を押してフォルダを選択すれば出来ます。
Linux版chia-guiを使ってみて
本体ソフトの操作感はWindows版と全く変わりませんでした。ちょっとインストールが手間ではありましたが、chiaのディレクトリ構築はインストール時のログを辿っていたのでなんとなく把握することができました。plot時に使用するソフトの位置も把握できたので、コマンドラインからplotファイルの作成か可能そうです。これが出来れば今後はshellスクリプトとしてコードを書けるので、plotファイルをhddの容量がいっぱいになるまで自動で走らせる事が出来ますね。また、plot作成時のログも取得して整理しながら別ファイルに追加で出力する事も出来るので、並列作成する際のdelayも何分に設定すればいいかも決められそうです。
chiaマイニングの現状と今後、hpoolの状態、そしてこれからやるべき事
初めに
今回の記事はあんまり技術的な事は無いです。githubの解読とhpoolの状態を監視している内容になります。
まずはhpoolについて
2021/5/25現在ですが、hpoolの新規会員登録が一時停止しています。理由はよく分かりませんが、止まっています。自分はhpoolにまだ登録していなかったので、正直こうなると登録再開してもどうしようか悩む状態です。理由は後述します。
また、5/22 16:00以降にアカウント登録した物に関しては、追加で認証が必要になっているらしいです。これに関しては自分はhpoolのアカウントがないので中の状態を確認できませんが、hpoolのお知らせに書いてありました。
公式poolに関して
どちらかというとこちらがメインの話題です。
現状chiaのテストネットでは公式poolの実装に関するテストが進んでいるらしいです。公式の呼称をそのまま流用すると、現状自分も含めてみんなが作っているplotファイルをOG plotと呼び、近々リリースされる新しいplotファイルの呼称はportable plotらしいです。
公式poolがリリースされるとportable plotでの採掘も可能になるらしく、個人採掘はOG plotとportable plotの両方が対応し、poolでのマイニングはportable plotのみが対応する形に変化すると記載されています。また、OG plotとpoortable plotの互換性はないらしいです。そのため、公式はOG plotからportable plotへの移行を勧めています。
portable plotの作成ツールは5/31までにgithubに公開されると言っています。そして公式poolのソースは6月以降にリリースすると言っています。
では、公式poolがどのような感じになるかという事ですが、githubのFAQには以下のように書いてあります。
Chia has three major differences from most other crypto pooling protocol: 1) Joining pools are permissionless. You do not need to sign up to an account on a pool server before joining. 2) Farmers receive 1/8th of XCH rewards plus transaction fees, while the pool receives 7/8th of XCH rewards. 3) The farmer with the winning proof will farm the block, not the pool server.
要点だけまとめると、
・hpoolやNiceHashみたいにアカウントを作らずにpoolに参加でき、chiaサイドが自動でマイナーに対して報酬を分配する
・マイナーはpoolに対してパワーを提供するのではなく、参加者全員が直接ブロックを採掘しに行く
・pool参加者が掘り当てた際に、掘り当てた本人は1/8の採掘報酬と手数料を入手出来、pool参加者は残りの7/8をパワーに比例して分配される
こういうことらしいです。
まあ確かに、今までに無い形のpoolで、かつセキュリティ的には秘密鍵を本人以外に公開しないという点ではかなり優秀な形になっていると思います。
現状のhpoolとchia公式の見解
githubを読んでて分かったのですが、hpoolが使用しているchiaクライアントは公式chiaが作成した物のソースコードを改変してhpoolへアクセスできる機能を追加した物らしいです。そのため、最初に秘密鍵の登録のステップなどが残っています。その後、hpoolへのAPI Keyを登録して掘り始める形になっています。chia公式はそこに対するセキュリティ的な危険性を指摘しています。まあ、利用者なんてそんなこと分かっているのですが。
また、調べていると他にも出てきたのですが、現状hpool自身がハッシュパワーの4割弱を保持している状態になっています。これはchiaに限らず全部のブロックチェーン系通貨に言えることなのですが、悪意を持ったマイナーが全ハッシュパワーの50%超を保持した場合、取引トランザクションの承認・改変が可能になってしまいます。今までの暗号通貨は競争率によってこの状況を回避してきたのですが、hpoolはこのまま唯一のpoolになってしまうとこの危険性が現れてきます。また、chiaに対する攻撃だけでしたら30~40%のハッシュパワーの保持のみで可能です。chia自身はこれを恐れている可能性がありますね。
3年前の記憶ですが、確かに仮想通貨が実装された時もこれに関しては話題になったのを思い出しました。もともと仮想通貨はトランザクションの承認を分散させる事によって相互に結果を確認し不正取引を防ぐことがコンセプトでした。確かに現状のchiaではこれの対策がちょっと怪しい状態にはなり始めていそうですね。
じゃあ自分としてどうしようって話
自分的にはchiaは久しぶりに見つけた面白そうな物なので、このまま廃れては欲しく無いですね。なので、公式poolが実装されたらそちらには移動していく予定です。
それを前提において、5/25現在から6月までに何をしようかという事。
・portable plotのソフトのリリースに対して準備しておく
・hpoolの会員登録は再開されたら作るだけはするかもだが、公式poolが実装されたらそちらを優先して使用する
予定ではportable plotのソフトは数日中にリリースされます。リリースされたタイミングですぐにplotファイルの作成に取り掛かれるようにhddの調整とOSの調整を行う予定です。具体的には、今後はplotファイルの作成もマイニングする機材もlinuxに変える予定だったので、このタイミングでUbuntu 20.04を実機にインストールします。自分としてはlinuxの方がコマンドラインやssh系統が使い慣れているので。また、ログの監視や解析も行う予定なので、それを行うのならばlinuxでshellスクリプトを書いた方が慣れていて楽なので。
他には、ちょうどplotファイルを稼働させる側の機材も数日中に届きます。そちら側の組み立ても行い、Ubuntuのインストールを行いたいと思います。最終的には全部Ubuntuでの稼働を想定しています。WindowsはメインPCだけで十分です。自動更新切ったり省電力設定を調整したりしなきゃいけないし、そもそもUIで結構処理能力を食ってしまうのでスペック的に勿体無い感じがします。
公式poolが実装されたら本格的に報酬を得るために参加しようと思います。plotファイルの作成に関してはとりあえず1TB分だけ作って様子をその後見ます。報酬次第では追加投資も考えます。hddも安い所を見つけたので、損益分岐点はかなり低めになりそうです。
正直公式poolがどれぐらい報酬を吐いてくれるか分からないので、それ次第といった所ではあるのですが。ただまあ、今までに買った機材はまだ実用可能範囲に収まっているので、現実的にはまだchiaの触りぐらいにしかいない感覚です。
とりあえずportable plotのソフトがリリースされたら最速で触ってみて記事にしようと思います。
終わりに
今回は現状の解析と考察だけです。メモ書き程度ですが。
それではまた。
chiaマイニングにおけるplotファイルの作成と速度の測定
ちょっと初めに
前回の記事を書いた後に、昔記事を書いていた時にとてもお世話になっていたサイトの主さんにTwitterでDMを送りまして、相互リンクを貼らせて頂きました。それに伴いtopページのレイアウトもちょっと変わりました。
こちらのサイトです。
自分より早くchiaに対してアクションを起こしているので、参考になる記事はとても多いです。また、自分では実装しようと思って先送りになってた10Gbps環境も整えているらしく、ちょっと憧れています。自分の家では基本的に大容量ファイルは扱わず、ファイル管理はローカルPCの中で完結させているため、10Gbpsや光ファイバーはロマンの領域なので、優先度がちょっと下がってしまっていました。また、稼働しているPCが5台ぐらいあるため、全部対応させようとすると20万ほど飛びそうなので。nuro光も引いていないので外部とのアクセスはcat5eの帯域限界で頭打ちですし。ただ今後、完全remoteでplotファイルを作成する可能性を考慮すると一部だけでも整えるのはありなのかなと思っています。
今回の実証環境
今回、元々apacheサーバーとして使っていたPCを流用しました。そのため、最初の測定機材はかなりポンコツです。
検証機材その1
CPU:AMD athlon 220ge 3.4GHz 2core 4thread
memory:DDR4 8GB
GPU:Onboard Graphic
OS:Windows10 on 120GB SSD
temp folder:500GB HDD
final folder:1TB HDD
検証機材その2
CPU:AMD Ryzen5 2600
memory:DDR4 8GB*2
GPU:GeForce gt710
OS:WIndows10 on 120GB SSD
temp folder:NVMe 1TB
final folder:1TB HDD
前環境のPCはマジでapache用のテストサーバーとしてしか使ってなくて放置していたため、OSが120GB SSDに入っていて、メモリーがちょっとだけ積んであるathlonを使いました。実際に1plotだけ作ってみて、所要時間とボトルネックの測定をしようと思っていただけです。
その2の方は今回少々機材の買い足しをしまして、それにおけるボトルネックを調べてみようと思い組みました.正直実際に作成してみないと実際にかかる時間とどこの性能を上げたらいいのかわからなかったため、適当に機材を揃えました。
んじゃあ、実際にかかった時間の記録を。
実測定時間等の記録
まずは最初のポンコツ環境の所要時間
1plot 101.4GiB memory 4GB 2thread
12h10min
これは、実際にプロット作成をしながらスペックの余裕を見ていたのですが、CPUの使用率が80〜90%と若干ですが空きがありました。ただ、瞬間的には100%に張り付くタイミングがあったので、少々CPUスペックは足りてなさそうでした。メモリーの方は割り当て自体はかなり余裕がある感じで、実際は2GBも使っていない感じでした。1番のボトルネックはtempファイルを置くスペースがhddだったという所でした。こちらに関してはRead/write共に100MB/sにほぼ常時張り付いてしまい、真っ先に修正すべき点でした。ただ、このままNMVeに切り替えてもCPUの余裕がなさそうだったので、CPUも同時に買い替えです。
では、2番目の少しつよつよPCでの所要時間
1plot 101.4GiB memory 12G 10thread
8h9min
タイムとしては4時間ほど縮まりました。これに関してはかなり良いタイムではないでしょうか。公式が書いていた9~12時間かかると言うデータはタイム的に切ることが出来ました。ただ、これに関しては、プロット作成をしながらPCの状態を監視していたのですが、NMVeの温度が75〜80度に張り付いてしまいました。ピーク時は92度という数字でした。自分としてはこの温度を見るとマイニングをやってるなと思って感動していたのですが、感動している場合じゃありませんね。
今回NMVeにはヒートシンクも取り付けておらず、転送速度に上限を設けていなかったのでこの温度になるのは仕方ないといった気分ではありますが。ケースファンも面倒だと思って一個も取り付けなかったので。
エラーに対するアクション
じゃあ、並行処理でplot作成をしてみたら所要時間はどうなるのかと思ってちょっと設定を弄って作ろうとしました。何回かやってるうちに色々なエラーに遭遇できたのでそれぞれ記録しておきます。
1.Error 1. Retrying in five minutes.
こいつは、tempファイルを作るディスクの空き容量がない場合に吐かれるエラーです。どうやら、plotファイルを作る際のtempファイルは終了時も消されないらしく、連続して5個目のplotファイルを作ろうとした時に怒られました。まあ単純に240GBぐらいのファイルを5個作れば1TBを超えるよなそりゃ。ただ、作成完了時にtempファイルを消してくれないと言うことを学べました。これは、将来的にLinuxでコマンドで作成する際はフォルダ分けして、作成完了時にrmコマンドを走らせた方がいいですね。今後のために忘れないようにしておかないと。
※追記
このエラーなのですが、2plotの並列でも同様の物を吐かれました。このエラー、引き起こされる要因は複数あるっぽいです。今原因を探していますが、NVMeのフォーマット形式が悪かったり、plot中にアクセスが省電力により途切れたり、メモリー不足により引き起こされたりと少々面倒そうなので調査しています。分かり次第追記します。
少々エラーを無理やり再現して分かった結果は、tempファイルを保存しているデバイスがplot作成中に取り外されるとこのエラーが吐かれるようです。今回自分の環境ではNVMeがWindowsのPCIポートに対する省電力モードによって稼働可能電力以下まで落ちてしまい接続が切れてしまったのが原因だったらしいです。
解決策としては、Windowsの場合、「設定」→「電源とスリープ」→「電源の追加設定」→「バランス」の横の「プラン設定と変更」→「詳細な電源設定の変更」→「PCI Express」→「リンク状態の電源管理」→「設定」の項目を「適切な省電力」から「オフ」へ変更
これによりNVMeを接続しているPCIポートへの省電力モードがオフになります。
tempファイルを外付けドライブなどに保存している場合は、USBポートに対する省電力モードを切っておくとこのエラーは回避できます。
2.bad allocation errors
こいつは、メモリ割り当てが少なすぎるよって言うエラー。今回これを引き起こした理由としては、単純にplot作成時の設定で割り当てメモリの0を一個打ち忘れて、12000MBとしたかった所を1200MBと打ったことでした。まあそりゃ1.2GBでplotファイルを作れるわけないですよね。
3.そもそもNVMeがWindowsから認識しなくなる
これに関してはマジで原因がわかりませんでした。また、困ったことに治ってしまったんです。症状としては、
・UEFIからNVMeが認識しない
・デバイスマネージャーから確認するとPCI portのNVMeに関するドライバエラーが出ている
・WindowsはGUIDが記録されていればマウントは自動で行うため、ドライブとしては認識しているがアクセスが不可能
一時的にNVMeをメインPCに差し替えて起動確認もしたのですが、同様のエラーが出ていたところから、マザーボードやOS側のエラーではない事は確か。つまり、NVMe M.2がイカれた可能性が高そうです。差し替えて起動しない方が原因の切り分けは面倒だったので認識しなかった事で助かりはしたのですが、これはこれで面倒です。
考えられる原因としては、1番はやはり高温によりNVMeの稼働限界が訪れた可能性ですね。これはこの作業をやっていくにあたってかなり本格的に対策しないといけ無さそうです。ただ、何が面倒って、GPUと違ってNVMeは基盤に並行に貼り付けて使う形なので、どうしても冷却が完璧にできないという事です。一応小型FANがついているヒートシンクも売ってはいるのですが、正直小型FANでどうにかなるレベルを超えていそうな感想です。これに関しては対応を考えますが、簡単な対策ならM.2用ヒートシンクと高回転FANを買って風を直当てして無理やり冷却する、非常に面倒な対策としては水冷用M.2水枕を購入して一部簡易水冷を回すという方法。水冷に関しては必要費用がバカにならないのでやる可能性は低いですが、ヒートシンクで対応出来ないレベルでしたら対応策として考慮しておかないといけ無さそうです。あとは、PCI x16拡張ボードで本体から隔離してそちらで冷却機構を作る方法も良さそうです。まあ今後NVMeでraidを組む可能性が出てきたら拡張ボードは買わなくてはいけないため、そしたらその際にやろうと思います。
ちょっと技術的な事
エラーログとスペックの調整において多分知っておかないとキツそうな事をとりあえず見つけたので記録しておきます。元記事はこちら。
https://medium.com/geekculture/chia-network-plotting-optimization-7f0d6380eded
chiaのplotに置いて作り始めから作り終わりまでをphaseという形で管理されています。Logを見るに1~4があるらしいです。ただ、この記事を参考にすると、phase5が一応存在はしているらしいですね。内訳を要約して書いておきます。
phase1:plotファイルを作る際にどの計算をしなければいけないかリストとして出力するphaseです。このタイミングでtempフォルダに0byteファイルが大量に生成されます。ファイル名に計算内容が記載されています。また、このタイミングで割り当てメモリの確認も行われます。上記に発生したメモリ割り当てエラーなどはこのphaseで起こります。
phase2:ここでは演算を主に行なっているらしいです。あとは余分だった演算の削除を行なっています。ここのphaseが1番CPUを食っている印象があります。
phase3:ここではファイルの整理と圧縮を行なっています。一時的にphase2での演算結果は膨大なファイルサイズになっているので、それを可逆的な形式でコンパクトにしています。実際にどのようにファイルを整理しているかは元記事を参照していただければ。
phase4:ここでは最終的に圧縮と確認を行なっています。そして単一ファイルになるように調整しています。
phase5:tempフォルダからfinalフォルダに対して演算結果の最終ファイルをコピーするphaseです。このタイミングでhddの読み書きが初めて発生しています。
このロジックを理解していると、今後並列plotを作成する際にどのぐらい遅延を発生させるのがCPUとNVMe的に1番負荷がないかが分かるはずです。実際にデータを取っていないので現状は推測ですが、phase1.2では主にCPU、phase3.4では主にメモリとNVMeへのアクセスが高負荷になっている印象です。つまり、plot作成時にphaseと時間が対応するようなlogファイルを吐かせて、ちょうど処理が切り替わるタイミングで次の作業を開始されれば1番効率よく作成できそうです。ただ、logファイルを上から吐かせるならlinuxでの作業の方が自分は慣れているのでこれは作成用機材をlinuxに変えてからやろうかと思います。
最後にちょっとだけ
とりあえずwindowsで1TB分のplotはテストで色々弄りながら作り切る予定です。それが終わったら機材の調整をして、OSをLinuxに変えて環境構築をして、1TB分をpoolに入れて稼働させて収益を見てみようと思います。それ次第では追加で4TBhddを購入して一気に作成を始めようと思います。まあここまでは転がっているhddでのテストなので、追加投資している部分はNVMe 1TB・Ryzen5 2600・SSD 120GBの3つなので今後使い回しが効く機材です。まあこれだけでも28000円ぐらいはしているんですが。
あと、amazonでちょっと家に足りなくなってきたスペア部品を発注しました。具体的にはA320M-HDV R4.0という型番のマザーボードとFSP 80+ 550W電源ですね。こいつら2つで10000円ぐらいです。これは今回外したathlonを刺して転がっているメモリを刺して、買ってきたSSD 120GBにOSを入れてplotが終わったHDDを稼働させるPCにする予定です。これも組み終わって調整ができたら記事にしようと思います。
正直机の横のスペースがなくなり初めて、作業用デスクを侵食し始めました。サブモニターも追加で欲しいし、必要な機材はめちゃくちゃ多いです。chiaの相場が落ちなければいいなぁと思いながらplotファイルを作っています。サーバー用機材も欲しいし、PC部品はいくら買ってもキリがないですね。
では、また進捗があれば記事にしようと思います。
それではまた。
chiaマイニングに対するファーストアタックとその結果
初めに
まずは、前回の記事をきっかけに3年ぶりにこのブログを再開した理由ですが、chiaマイニングを少し興味を持ちまして、興味が出たなら触ってみるという話でして、まあ忘れないように記録したかったという理由もあります。単純にnextcloudの構築に丸3日かかったことに対して記事の無さに苛立ちを覚えたというのもありますが。
ということで、chiaマイニングです。とりあえずは家に転がっていた機材で必要性能チェックと試算、それに対する結果を記録していこうと思います。
chiaマイニングとは何か・plotにおける特徴とburstとの違いなど
端的に言えば、hddマイニングです。今まで流行っていたGPUマイニングは演算の計算式がこちらに飛んできて、計算結果を相手に返すというロジックに対して、hddマイニングは容量の足りる範囲で演算結果を事前に計算して記録しておきます。そして向こうから飛んで来たものに当該する結果を保持していた場合結果を返答します。昔はburstコインという通貨が同じロジックを採用していました。3年前にマイニングを触っていた層なら馴染みがあるでしょう。
では、burstとのマイナーサイドの大きな違いをひとつ。それは演算時のtempファイルを別ディレクトリに作成できるという点です。これに関しては非常にplotファイルの作成が捗ります。burstの頃はplotファイルを作成するディレクトリに直接演算結果を書き込んでいたので、書き込み速度が限界に達していたことが多かったのですが、今回NVMeなどにtempファイルを置き、演算結果を最終的にhddに動かすという事が出来ます。というか自動でやってくれます。burst時代は手動かスクリプトを組んでました。まあただ、これが理由でtemp側の記憶媒体の寿命はマジで馬鹿みたいに削れます。NANDチップに書き込むという点で発熱もやばいですし、元々hddに比べて耐用年数は低めの物なので仕方はないですが、それにしても異常な速度です。
では、次はchiaコインの環境構築とやり方について。
環境構築と初期設定
まずは最初に公式clientをダウンロードします。
今回はwindowsで環境構築をしますが、どうやら海外の記事でwindowsでのplotファイルの作成よりもlinuxで作成した方が10~20%作成時間が短縮できるといった記事を見つけたので、今後linuxに環境を移行しようと思います。その際は自動化のスクリプトをも組んでいく予定です。
ダウンロードリンクはこちら。
Home - Chia Network
上の方のWindowsがリンクになっているので、こちらをクリックしてclientをダウンロード。直接exeが落ちてきます。
起動したらfirewallを開けろと言われるので開けます。
そしたら、今回は新規導入なので、walletを作成します。CREATE A NEW PRIVATE KEYをクリック。24個の英単語が羅列されるので、これを記録しておいてください。公開しない・無くさないに気をつけてください。最悪後から再度確認は出来ますが。
nextを押したらメイン画面に飛びます。もういっかfirewallを開けろって言われますのでokします。

こちらがメイン画面。多分最初はstatusの項目がSyncingとなっているはずです。公式のやつはchainをローカルに落とし込む必要があるので、その同期の進捗が出てます。これが完了してSyncedになれば終わりです。まあ半日から1日で完了します。ちなみに、これが完了してなくてもplotファイルの作成には取り掛かれるので、まあ放置して定期的に確認すれば大丈夫です。
そしたら早速plotファイルの作成に取り掛かります。
plotファイルの作成
まあまずはplotファイルの作成から。左のPlotsのタブを押して、ADD A PLOTを押します。ここから作成に関する設定をして作成を開始します。設定項目は以下の感じ。

ちょっとサイズが大きすぎて画面を跨いでしましましたが、必要な場所は写っているのであしからず。
上から
1.plot size
2.number of plot
3.temp directory
4.final directory
この項目を設定します。
1.plot size
これは基本的には101.4GiB(temp:239GiB)で大丈夫です。サイズが上がるとplotファイルの耐用年数が上がるのですが、101.4GiBで7年ちょいは持つらしいので問題なさげです。というか、これ以上大きくすると微妙にhddの容量からオーバーする可能性があるので、これがいいです。
2.number of plot
同時に何個作成するか、作成時の処理に割くスペックの設定欄です。
plot countは何個101.4GiBのファイルを作成するかという事。今回は転がっていた1TBのhddを使っているのでとりあえず9個としています。ただ、実際は1個だけ作って中止しています。
下の折りたたまれているAdvanced optionを開きます。その中をちょっと弄ります。
その前に一応今回使ったPCのスペックを
CPU:AMD Ryzen 3900X(12Core/24thread)
RAM:32GB
SSD:500GB
HDD:1TB
MB:X570 Aqua
Power:1200W
GPU:GTX 1080Ti *2(SLI)
今回自分はメインPCの余っているリソースで作成したので、RAMは余裕を見て10G割きました。ただ、やってみてこんなに要らなさそうでした。実際は1840MBぐらいしか使っていませんでした。並行して作成する場合、1plotあたり1.8GBぐらいを目安にしておくといいかもです。
number of threadsは作成に割くCPUのthread数です。今回はタスクマネージャーを見ながら10threadは余っていたのでその量を割きました。ただ、これも作ってる際は10thread使ってはいたのですが、各thread30%ほどしか使っていなかったので、1plotあたり3〜4threadでいいのかもしれません。
残り2つはそのまんまで大丈夫です。まあ名前を覚えやすいように変えてもいいかも。
3.Select Temporary Directory
tempファイルを保存する場所を指定します。ここに関しては読み書きが早い場所を指定することをお勧めしますが、寿命が犠牲になります。今回は時間をかけてもいいということでhddを割り当てているDドライブを設定しましたが、結論から言うと12時間かかりました。マジでアホなんじゃないかという感じ。
4.Select Final Directory
最終的にファイルを保存する場所を指定します。これは最後のプロセスで一気にデータを動かすため、読み書きはさほど問題ではなさそうです。とにかく容量が必要ですが。自分は外付けでhddを1TB付けているので、そのディレクトリの直下を指定しました。Fドライブですね。
とりあえず項目の指定が完了したらCREATE PLOTを押します。そうすると画面が移行してplotファイルの作成が始まります。
plot作成が終わると
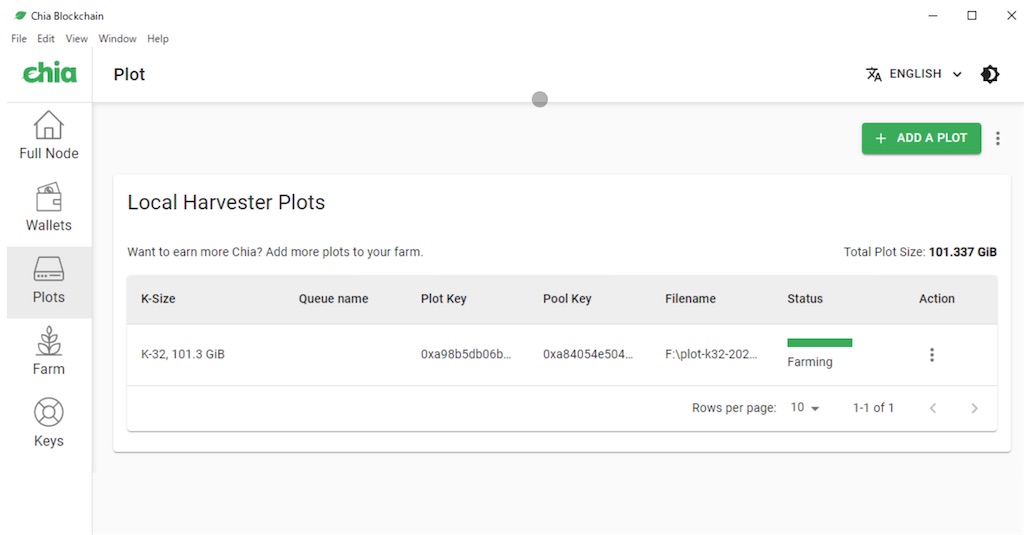
こんな感じになります。終われば自動的にマイニングを始めてくれます。とりあえずplotファイルを作成できたので良しとします。
ちょっと考察と今後についての方針決め
じゃあ、今回のことを踏まえてどうしようって言う話。
Final directoryはさほど作成時間に影響ないとして、temp directoryをメインに焦点を置いていきます。
chiaの公式blog曰く
「ガチのプロが101.4GiBのファイルを1つ4時間ちょいで作成、普通のプロが5時間ちょいで、一般人は9~12時間で作成出来ます」
といっています。
Chia plotting basics
今回12時間かかったので、hddでの作成は理論値最大でかかるということらしい。今後の調整は9時間を目安にしていこうと思います。
じゃあどうするかっていう話。
とりあえずNVMeを買う予定です。メインPCの容量もちょうど足りなくなってきたので、それのついでで買おうかと。plotファイル作成用PCの作成ですが、1thread性能もある程度必要で、thread数もある程度必要、かつ安価なものってなるとryzenもいいのですが、intelのskylake時代のものが型落ちになってきていていい感じかもしれません。ちょっと相場を調べてみて決めようと思います。ryzen初期型は対応マザーボードがなぁって感じ。
メモリーはとりあえず4〜8程度積んでおけばよさそうかも。使ってて足りなくなったら増設しようと思います。
今後についてですが、とりあえずplotファイルの作成高速化と、転がっている1TBを全部埋めて、HPOOLという非公式chiapoolに投げ込みます。んで収益をみて収支計算をして、損益分岐点を見極めてみて、実際に投資するかどうか考えます。環境を整えるのも大変なのでちょっと時間はかかると思いますが、1ヶ月程度を目安に試算を完了しようと思います。
とりあえず1台分のPC部品は余っているのですが、これ2台分必要なのでもう1台の構成を考えて買ってこないとなぁって感じです。
何かしら進捗があればまた書き進めていこうと思います。
それではまた。
Ubuntu20.04にraid0を構築してsnap版nextcloudをインストールした話(最初に少々マイニングの話)
序章
お久しぶりです。最近はめっきりマイニングからは手を引いてしまっていたのですが、情報だけは集めていました。その中でもhddマイニングでのchiaマイニングはburstマイニングを少々連想させられていました。あの頃よりは通貨自体の相場が高めなので割に合うのかなといった感想でしたが、hddマイニングの界隈は数百TBからPB単位に突入するレベルの人たちが参入してきたり、burstの頃と違ってマイニングプールが存在しないことからchainの一本釣り感がある印象のため、すぐにhddの元が取れなくなったり収益概算値がめちゃくちゃ不安定じゃないのかなぁと遠目に眺めていたら案の定といった感じでした。GPUマイニングよりもhddマイニングはより手軽に参戦出来ますが、圧倒的に参入勢の使用容量が桁違いのため、数TBもあればいけるやろといった感覚は結構外れたりします。あと、plotファイルの作成に非常に時間がかかったりとちょっと悩ましい点もありますね。自分はburstコインの時はplotファイルの作成用にRyzenを新調してました。
(5/19に末尾分追記)
記事作成の理由
今回この記事を書いた理由として、nextcloudに関する記事が日本語ではraspberryPiに対するものしか無く、自分かこれを構築するにあたってめちゃくちゃ海外のフォーラムを漁りまくっていたので、誰かの助けになればと思って書いています。
ちなみに、raspberryPiだとUSB接続にて外部ストレージを読み込ませるのですが、PCとして構築する場合はSATAケーブルにて繋ぐため、少々手順が変わってきます。また、今回raidを構築するため、間に数ステップ追加されます。それに関してもちょっと手間取ったのでメモ書きとして残します。
構成
まあchiaの話はこれぐらいにして、今回の本題であるnextcloudの話を。
今回これを自宅に構築した理由ですが、身内10人程度での大容量クラウドサーバーが欲しいということになったのですが、NASだとローカル環境でしかアクセス出来ず、sshを介してしか使用出来ないため、PC初心者も混じっているメンバーだとsoftEtherなどの導入は難しく、結果nextcloudの構築となりました。PCの構成は以下のような感じです。
・Intel i7 6700k
・MAXIMUS VII HERO
・DDR4 2133 4GB*2
・ADATA SSD 120GB
・SEAGATE 4TB*3
・450W Thermaltake
構成自体は、正直床に転がっていた部品を全部使ったため、新調したものは無かったです。HDDに関してはburstマイニングの頃に使っていた物の余り物なので、正直ちょっと寿命が心配ですが、そこは根性でなんとかします。
Ubuntu20.04の導入
とりあえず、まずはOSのインストールということで、isoファイルをダウンロード、RufusでUSBに焼いてインストールをします。これに関しては手順は山のように記事が転がっているので省略します。それぐらいは自分でできる人じゃないと今後のことは出来ないため。
今回、OSは120GBのSSDに導入します。
RAIDの構築
とりあえずOSはインストール出来たとして、RAIDを構築していきます。今回はソフトウェアRAIDということでmdadmを使用していきます。まずは使用しているディスクの名前の一覧を
sudo fdiski -l
自分の構成だと、4本記憶デバイスが刺さっているため、これらが/dev/sda,/dev/sdb,/dev/sdc,/dev/sddとして認識しているのが把握できます。今回OSは/dev/sdaにインストールしてあり、残りのsd[bcd]が4TB HDDのため、これらでRAIDを構築していきます。
まずはRAID構築用ソフトのインストール
sudo apt install mdadm
この子はソフトウェアRAIDを構築するためのソフトです。
そしたらこれを使ってRAIDアレイを作成します。
sudo mdadm —create /dev/md0 —level=0 —raid-devices=3 -f /dev/sd[bcd]
なんか確認が出るのでyでおっけーします。
もしこの際なんかエラーを吐いたら、各デバイスにパーティションが出来ていないため、fdiskとかpartedでパーティションを/dev/sdb,/dev/sdc,/dev/sddに対して作っておきます。また、容量が2TBを超えるので、その点に関しても注意しながら。もしCUIでの作成がだるい場合はGUIでディスクって言うソフトでUIを使っても作れるので、それを使うと楽かも。
出来たら、mdadmで確認を
sudo mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed May 12 15:53:00 2021
Raid Level : raid0
Array Size : 11720658432 (11177.69 GiB 12001.95 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Wed May 12 15:53:00 2021
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : -unknown-
Chunk Size : 512K
Consistency Policy : none
Name : micotoserver:0 (local to host micotoserver)
UUID : 47ad2973:c59b4863:45b2d5ea:4c8e144b
Events : 0
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sddこんな感じで出てくれば、RAID0を3本使って構築が完了しています。
そしたら、fdisk /dev/md0でパーティションを作って、mkfs.ext4 /dev/md0を使って新しく作った/dev/md0をext4でフォーマットします。これが完了すれば、今回作ったRAIDが1つの領域として使用可能な状態になります。
RAIDをmountする
とりあえずRAIDの構築が終了したので、ファイルとして使えるようにmountします。今回は/mnt/nextcloudにマウントします。
cd /mnt sudo mkdir nextcloud
これでとりあえずフォルダを作って、
sudo mount /dev/md0 /mnt/nextcloud
こいつでマウントします。なんか特にエラー吐かずに出来れば、マウント出来てます。
再起動でも安定するようにconfigファイルを弄る
そしたら、サーバー再起動をしてもraidが正しく構築されて自動でマウントされるようにちょっとだけconfigをいじります。
reboot時に自動でやって欲しいことは
・raidArrayの構築
・/mnt/nextcloudに/dev/md0のマウント
この2つなので、それぞれ書きます。
まずはraidに関して。いろんな記事を見てると/etc/mdadm/mdadm.confに書けば再起動時に自動でやってくれるらしいんですが、自分はなんか上手くいかなかったので、/etc/rc.localに対して記載しました。
#!/bin/bash mdadm --create /dev/md0 --level=0 --raid-devices=3 /dev/sd[bcd] <<EOF y EOF mount -a
mdadmのraid構築の際のyの入力はEOFで飛ばして、マウントに関してはmount -aでやってくれます。ただ、このmount -aはconfigファイルに書いてあるmountをやってくれるコードなので、それのconfigも書きます。
そいつのファイルは/etc/fstabにあります
UUID=***************** /mnt/nextcloud ext4 defaults 0 0
こいつを1番下に追記します。
このUUIDってなんじゃいってことなんだけど、これはblkidってcmdで打つと出てきます。
micotoserver@micotoserver:~$ blkid /dev/sda5: UUID="e3efa4d6-3d5e-4e28-afb0-4ad4ecc84077" TYPE="ext4" PARTUUID="40374a4a-05" /dev/loop0: TYPE="squashfs" /dev/loop1: TYPE="squashfs" /dev/loop2: TYPE="squashfs" /dev/loop3: TYPE="squashfs" /dev/loop4: TYPE="squashfs" /dev/loop5: TYPE="squashfs" /dev/loop6: TYPE="squashfs" /dev/loop7: TYPE="squashfs" /dev/sdc: UUID="47ad2973-c59b-4863-45b2-d5ea4c8e144b" UUID_SUB="a567ff5c-a293-f680-56e9-145a4816a105" LABEL="micotoserver:0" TYPE="linux_raid_member" /dev/sda1: UUID="D622-6E45" TYPE="vfat" PARTUUID="40374a4a-01" /dev/sdb: UUID="47ad2973-c59b-4863-45b2-d5ea4c8e144b" UUID_SUB="e7300202-3c01-8f5a-aea3-88a13c5e4a50" LABEL="micotoserver:0" TYPE="linux_raid_member" /dev/sdd: UUID="47ad2973-c59b-4863-45b2-d5ea4c8e144b" UUID_SUB="0918c5ca-1c1e-d7ef-a574-634dbd1a1ded" LABEL="micotoserver:0" TYPE="linux_raid_member" /dev/loop8: TYPE="squashfs" /dev/loop9: TYPE="squashfs" /dev/loop10: TYPE="squashfs" /dev/md0p1: LABEL="nextcloud" UUID="2cf83024-eda2-4bd5-80c3-43a9fd72d048" TYPE="ext4" PARTUUID="98893b25-1a08-49e1-b019-6fa34f645d9c"
これ。自分の場合は2cf83024-eda2-4bd5-80c3-43a9fd72d048になりますね。ちなみに、これで一応/dev/sd[bcd]がraidに追加されていることも確認できたり。
とりあえず、/etc/rc.localと/etc/fstabの編集で、再起動時にraidがうまく構築されるはず。一旦ここでrebootを入れて再起動後にraidが出来てマウントまで自動で出来ていれば成功。
次はnextcloudのインストールのお話。
snapとnextcloudのインストール
まずはsnap君のインストール
sudo apt install snap
なんかわーっといっぱいインストールされる。
ここからなんだけど、ちょっと一難あって、nextcloudをインストールする際に現在バージョンは最新20.0.9なんだけど、こいつ、いくら弄ってもクラウド容量(free space)が自分のインストールされてるパーティションしか読み込まなくて、今回みたいにraidの方にデータを保存して、nextcloud本体はOS側に入れたい場合、どちゃくそだるいので、インストールするバージョンを下げます。
まずはバージョンリストを取得
snap info nextcloud
わーっと出てきたら、今回は17/stableをインストールします。
sudo snap install nextcloud —channel=17/stable
ちょっとレイアウトは古くなるけど、正直認識しないよりは全然マシ。こいつなら上手く認識してくれました。
nextcloudの初期設定
そしたら初期設定をします。まずはadminUserの作成とアクセス可能なdomainの追加。
sudo nextcloud.manual-install UserName password
UserNameとpasswordは自分で変えてね。ここでadminアカウントを作成します。そしたら、アクセス可能なdomainの追加。
sudo nextcloud.occ config:system:set trusted_domains 1 --value=192.168.1.*
こいつで192.168.1.*からのアクセスが全般的に可能になります。他にもddnsを持っている場合はtrusted_domains 2としてvalueを変えて追加していきます。この追加を忘れると、localhostからのアクセスしか初期設定だと受け付けないため、ssh接続して操作してる場合、そのPCからローカルIPでブラウザで接続しても弾かれます。
その後は、データ保存先の変更。
nextcloudのconfig弄り
アカウントを作ったら、まずはデータをraidを作ったhddの方にコピーします。
sudo cp -r -d /var/snap/nextcloud/common/nextcloud/data /mnt/nextcloud
再帰させてディレクトリごとコピー。
コピー出来たら、アクセス権限の変更。これ、nextcloudの仕様なのですが、パーミッションを0770にしないと安全性の点から操作できないようになってます。なので、この辺を変えます。また、0770にしても保持ユーザーの関係からエラーを吐いたりするのですが、実は吐くエラーが同じなんですね。これに関してはマジで躓きました。
/mntから全部パーミッションを変更
sudo chmod 0770 /mnt -R sudo chown root:root /mnt -R
chmodで権限を変えて、chownで保持ユーザーと保持グループの変更。両方-Rで再帰させる。
次に外付けのメディアをnextcloudが読み込めるように設定します。
sudo snap connect nextcloud:removable-media
こいつ、/mediaにマウントしたUSBとか/mntにマウントしたHDDとかにnextcloudが読めるようにする設定です。
そしたら、保存先の変更。
sudo nano /var/snap/nextcloud/current/nextcloud/config/config.php
'datadirectory'の項目を以下のように変更
'datadirectory' => '/mnt/nextcloud/data',
これで変更完了。ちょうど直下に.ocdataっていうファイルがあるように編集してください。じゃないとまた怒られます。
このファイルは隠しファイルになっているため、探す際はls -alで探して下さい。
後は、好みなんですが、domainを取得している際はSSLを発行します。
SSLの発行
まずはファイアウォールを開けます。
sudo ufw allow 80,443/tcp
そしたらSSL発行
sudo nextcloud.enable-https lets-encrypt
これで発行。domain名とメールアドレスを聞かれますので記入していきます。自己証明でも発行はできますが、chromeだと自己証明のSSLは弾いたりするので、lets-encryptで発行した方が安全かも。
最後に確認
そしたら、http://localhostかhttp://ローカルIPでサーバーにアクセスします。なんかログイン画面が出ればオッケー。adminユーザーでログインします。最初に設定したやつ。
ログイン出来たらこんな感じの画面に飛べるはず。
ちょっとファイルとかアドレスは編集で隠してます。
右上のアイコンから設定に飛びます。
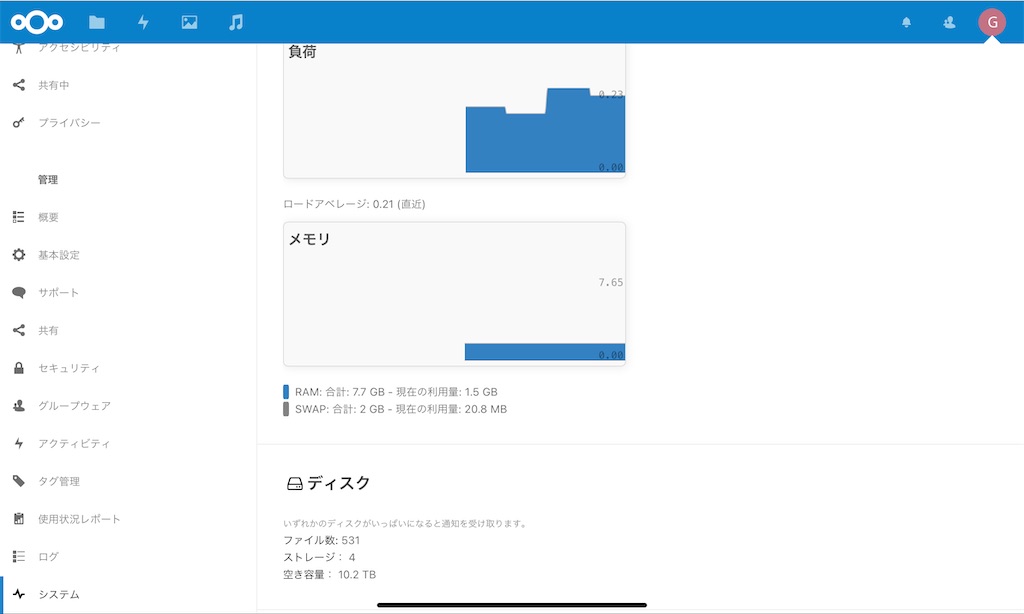
左の1番下にシステムってタブがあるんですが、その中にサーバーの詳細が入ってます。その中のディスクの項目がサーバーの容量です。上手く増設したHDDの容量になってれば成功。ちなみに、20.0.9のバージョンだとこれが何故かdatadirectoryを変えても自分の場合は100GBぐらいしか認識しませんでした。バージョンを17/stableに下げたら上手くいった。なんでだろう。
その他細かい設定関係
ちょっとだるいんですが、実はこいつ、初期設定だと16GB以上のファイルをアップロードで受け付けない用になってます。また、phpの使用メモリも512MBで割り当てられており、サーバータイムアウトも設定されてます。ここら辺を弄ります。12TBのサーバーを作ったのに70GBのファイルとか上がらないと悲しいからね。
sudo snap set nextcloud php.upload-max-filesize = 70G sudo snao set nextcloud php.post-max-size = 70G sudo snap set nextcloud php.max-input-time = 0 sudo snap set nextcloud php.memory-limit = 6G
この辺は各自自分のサーバーにあった数値に変えてください。
この辺に関しては、/var/snap/nextcloud/current/nextcloud/config/config.phpを直接弄っても大丈夫ですが、snapのコマンドから編集した方が気持ち安全かも。
他にも、snapでインストールしたnextcloudは、apacheもphpもsnap管理の元で動いているため、サービスの再起動を行う際のコマンドも特殊。
sudo systemctl restart snap.nextcloud.php-fpm.service sudo systemctl restart snap.nextcloud.apache.service
まあなんか、気持ち違和感。phpの設定とか変えた際はこっちで再起動。まあ面倒な時はrebootしちゃうんだけど。
終わりに
今回の構築に丸3日かかりました。まあ、snapのインストールに失敗して何回かubuntuの再インストールと、パーティションを間違えて弄ってbootファイルを見失ってend kernel panic起こして数回のubuntu再インストール、nextcloudを弄りすぎて壊れてubuntuごと再インストールを数回したのが原因なんですが。
安定したと思ったらhddを認識してなくていくら記事を探しても「あんたremovable-mediaをactiveにしてないんじゃない?」って書いてある記事しか出てこなくて、activeにしとるわい!ってキレてた。あと、記事を遡りすぎると古いバージョンはapacheとphpを別に入れてnextcloudをgitからcloneして構築する記事しか引っ掛からなくて、php.iniを探して編集してねって言われたけど、snapからのインストールだと実はそんなファイルなくて、なんなんだよ!!ってなってた。
3日目にしてやっと—channel=17/stableでインストールしてる海外の記事を見つけて、全部インストールし直してやってみたらすんなり認識して終わった。
んで、調べてて日本語記事はraspberryPiで外付けHDDを刺して構築してる記事しかなくて、しかもやるべきことが記事によってバラバラで困ったので、今回この記事を書いてみました。
まあ個人で大容量クラウドを構築する人なんてそうそういないと思うけど、誰かの助けになれればと思って。
それではまた。
5/19追記
chiaマイニングについて数日ちょっとだけ情報を集めてみたんですが、どうやら非公式でプールが存在するらしいですね(HPOOL)。また、公式もプールの開発には着手しているらしいです。プールが現状存在していて公式も開発の意思があるようなら、数十TBぐらいからならちょっと参入してもいいのかなと思ったりしています。
現状手持ちのHDDはnextcloudに12TB使ってしまっており、この子達は解体する予定がないため、参入する際は新規で少々HDDを購入しなければいけません。chiaの相場とHDDの相場、あとはプールのpayout率を監視しながらそこそこ真面目に計算して自分も参入しようか考えてみます。
ただ、plotファイルの作成にくそ時間がかかり、主な原因は演算よりもread/writeの方に問題があるらしいので、使い捨てのMVNeを考慮した方が良さげかも。演算用に昔買ったRyzenも別の機体に埋め込んでしまったので、そこら辺もちょっと考えながらHDD分の元が取れそうな気配がしたら参入していこうかと思います。その際は作成手順や計算結果もろもろを記事にまとめていこうと思うので、よろしくお願いします。
ethosMonitor ソースコードについて
Twitterでアンケートを取ってみました。そうすると、やはりマイニング用のものとあって、ソースコードが読めないから安心して使えないという意見がそこそこ存在していました。未だ投票は受け付けている状態ですので、ぜひ意見をもらえると嬉しいです。
ethos Monitor使ってくれてる人はいるのか
— 智咲命 アイワナ一発ネタ勢 (@micomico_tisaki) August 2, 2018
知ってるけど使ってない人に質問したいのですが、使用しない理由を教えてください
— 智咲命 アイワナ一発ネタ勢 (@micomico_tisaki) August 2, 2018
もし他に理由があればリプくれると嬉しいです
これですね。正直、「使いづらい」と「無くても問題ない」っていうのは修正のしようがないので頑張って改善して行くしかないのですが、ソースコードが読めないというのは確かに対策ができますね。
GitHub - MicotoTisaki/ethosMonitor
一応このままコンパイルをすれば使える状態です。自分もgithubを使うのは初めてなので色々苦戦はしましたが、多分見れるはずです。というか、cloneして自分で調整して使ってもらっても構いません。それでこのコードが日の目を見るのなら。
ということで、公開して使ってくれる人が増えるのなら全然公開しますので、ぜひ使ってください!
今後も色々ツイッターの方でも意見や投票を行っていったりするので、改善のためにもご協力をお願いします。
それではこの辺で。
ではまた。
ethosMonitor ver1.1公開
お待たせしました。とりあえずGPUの温度変化のグラフを可視化する機能を追加したのでアップデートのお知らせをいたします。

見られるグラフはこんな感じです。使い方としては、メインのパネルに存在するGPUの温度を表示している色のついた正方形のものをクリックすると別ウィンドウとして表示されます。
ただ、ethosdisrtoに保存されているデータ量がかなり多いため、表示には数秒かかりますので連打しないでください。
正直、自分でも保存されているjsonファイルを見た時に、読み込む量にちょっと嫌気がさして作成が遅れました。
現在新しく追加した機能はこれです。
現在、同じ様にハッシュレートも見れる様にし、また現在のハッシュレートやGPUの詳細なども詳しく見れる様に調整しています。そこらへんはまた追々。公開できるレベルまで調整できたら随時アップデートをして行く予定です。
ダウンロードリンクは以下になります。
また、アップデートの方法ですが、新しいethosMonitor.jarをダウンロードすると初期設定が書いてあるprofile.txtが付属します。前回のバージョンを使用している方は、その時のprofile.txtを上書きすると使用することができます。
これを引き継ぐことで、sshの設定やethosdistroのURLなどを設定せずに使える様になっています。
追加して欲しい機能やバグ報告などは引き続き受け付けております。コメントやツイッターの方に戴けると幸いです。
ではまた。